

La migración de datos entre repositorios heterogéneos (es decir, donde las bases de datos de origen y destino pertenecen a distintos sistemas de gestión de bases de datos de distintos proveedores) presenta varios desafíos. En algunos casos, es posible conectarse a ambas bases de datos simultáneamente. Sin embargo, hay ocasiones en las que simplemente no es posible. Cuando se les presenta un dilema de este tipo, los profesionales de bases de datos no tienen otra opción que rellenar las tablas desde un archivo de volcado. Navicat puede ser de gran ayuda en ese proceso. El Asistente de importación le permite importar datos a tablas/colecciones desde una variedad de fuentes, incluidos CSV, TXT, XML, DBF y más. Además, puede guardar su configuración como un perfil para su uso futuro o para configurar tareas de automatización. En el blog de hoy, utilizaremos el Asistente de importación de Navicat para migrar datos de la base de datos de PostgreSQL "dvdrental" database a una instancia MySQL 8 utilizando Navicat Premium Lite 17 GRATUITO.
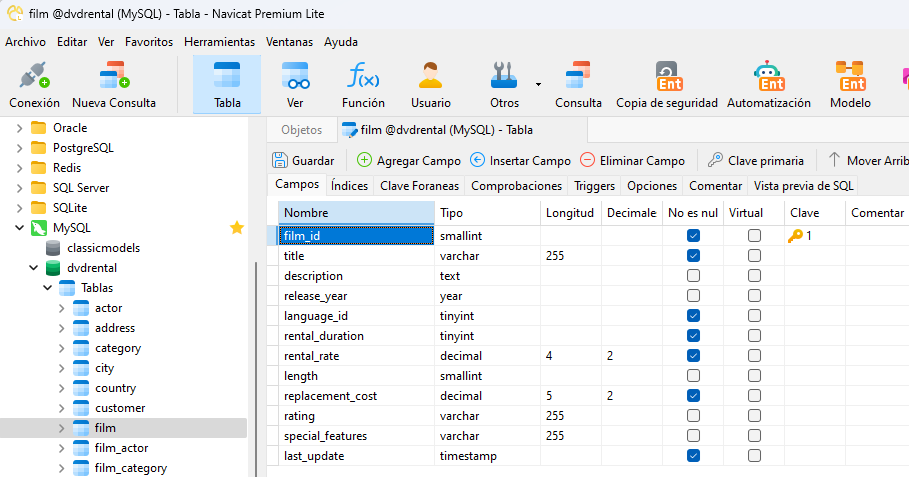
Para este tutorial, rellenaremos la tabla de películas en MySQL 8 utilizando el archivo DAT de PostgreSQL. Aquí está la definición de la tabla en el Diseñador de tablas:
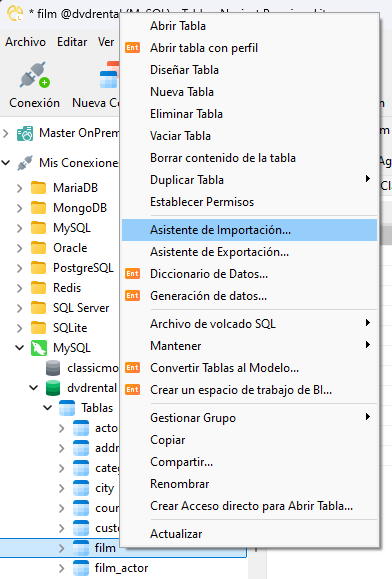
Para iniciar el Asistente de importación, haga clic con el botón derecho en la tabla de destino en el panel de navegación de Navicat (o mantenga presionada la tecla Ctrl y haga clic en macOS) y seleccione "Asistente de importación..." en el menú contextual:
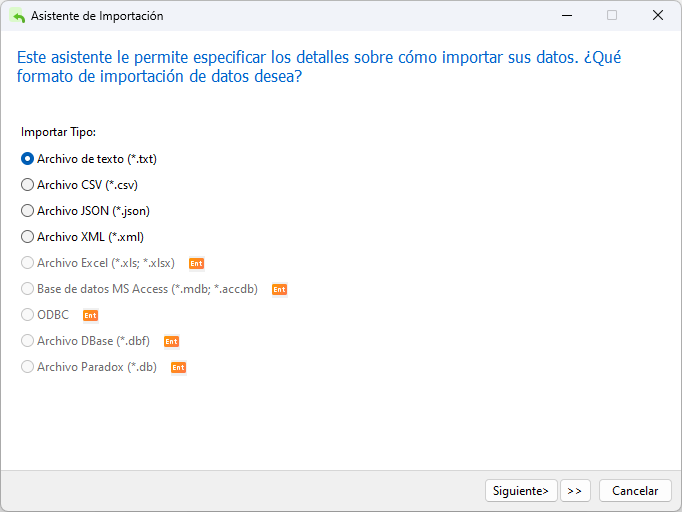
La primera pantalla del asistente es donde seleccionamos el archivo fuente. Tenga en cuenta que la edición Lite solo admite archivos basados en texto, como TXT, CSV, XML y JSON. Aunque tengamos un archivo .dat, podemos seleccionar la opción Archivo de texto, que abarca los formatos .txt, .csv y .dat:
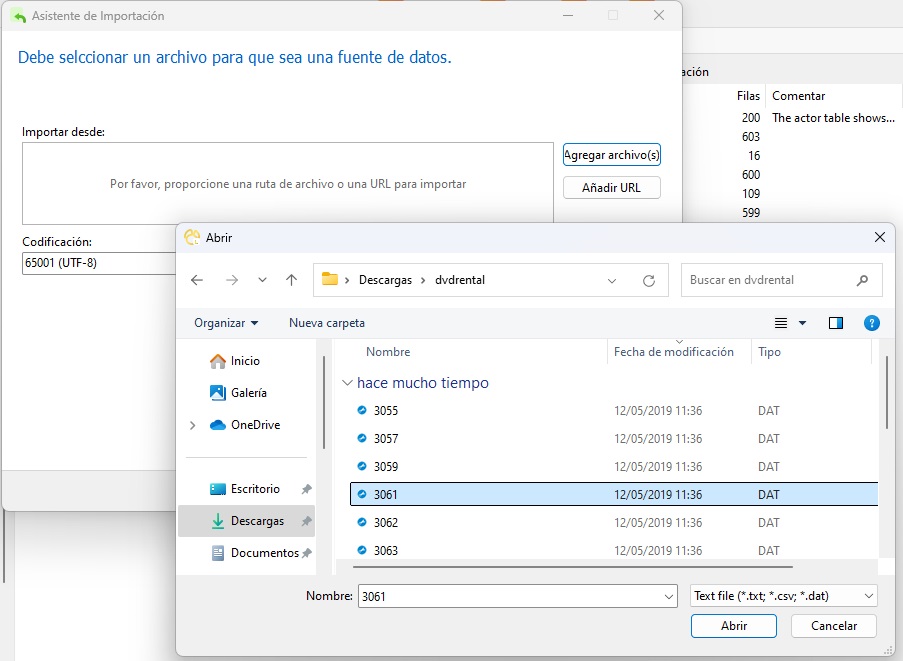
En la siguiente pantalla elegiremos el archivo DAT. Hay un archivo para cada tabla. El de la tabla de películas se llama "3061.dat":
A continuación, es el momento de establecer los delimitadores. Los registros se delimitan mediante el carácter de avance de línea (LF), mientras que las columnas se separan mediante el carácter TAB. No hay comillas alrededor de los valores de texto, así que asegúrese de eliminar el carácter de comillas dobles (") del cuadro de texto "Calificador de texto":
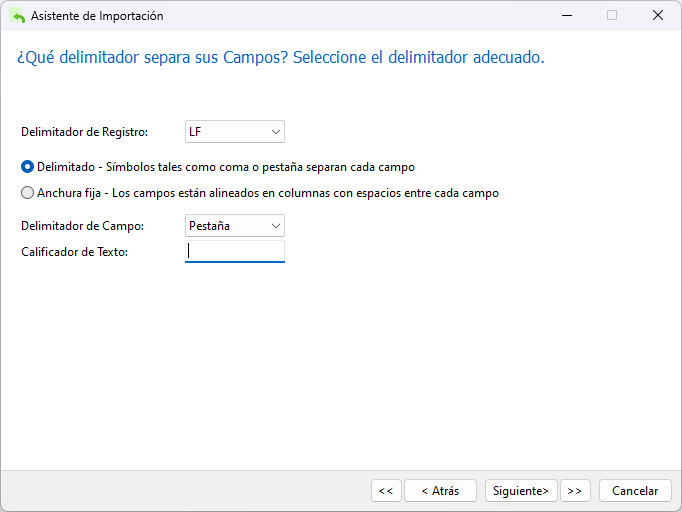
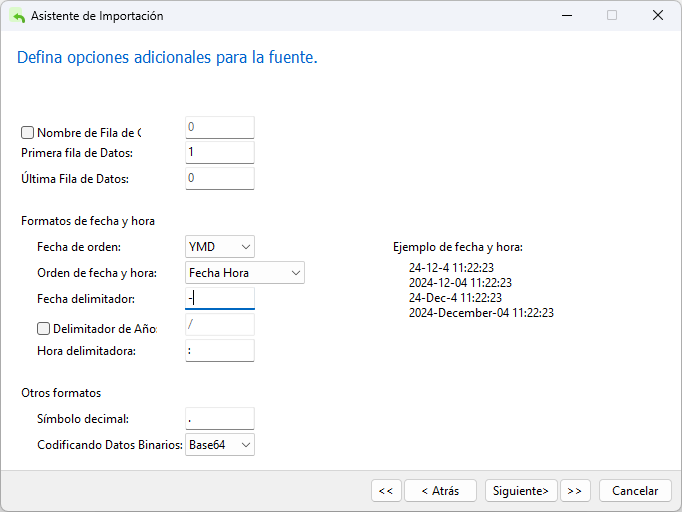
En la siguiente pantalla, encontrará algunas opciones adicionales. Aquí, tenemos que desmarcar la casilla "Fila de nombre de campo" porque el archivo DAT no incluye los nombres de campo. También tendremos que cambiar el orden de fecha a Año/Mes/Día ("YMD") y reemplazar el delimitador de barra diagonal (/) con el guión (-) ya que las fechas que vamos a importar tienen el formato AAAA-MM-DD hh:mm:ss.ms, es decir, 2013-05-26 14:50:58.951:
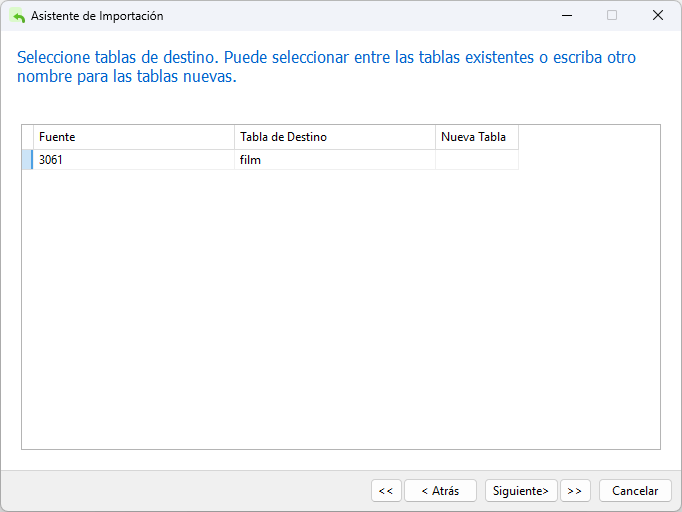
Tenemos la opción de elegir una tabla existente o crear una nueva. Dado que seleccionamos la tabla de destino al iniciar el Asistente de importación, debería aparecer aquí:
El siguiente paso es asignar los campos de origen a los de la tabla de destino. En este caso, no debemos asumir que se alinearán. Una mirada rápida a una entrada del archivo DAT revela que las columnas last_update y special_features están invertidas:
5 African Egg A Fast-Paced Documentary of a Pastry Chef And a Dentist who must Pursue a Forensic Psychologist in The Gulf of Mexico 2006 1 6 2.99 130 22.99 G 2013-05-26 14:50:58.951 {"Deleted Scenes"} 'african':1 'chef':11 'dentist':14 'documentari':7 'egg':2 'fast':5 'fast-pac':4 'forens':19 'gulf':23 'mexico':25 'must':16 'pace':6 'pastri':10 'psychologist':20 'pursu':17
Podemos hacer clic derecho (o Ctrl+clic en macOS) en cualquier parte del cuadro de diálogo y seleccionar "Coincidencia directa con todos" en el menú contextual para asignar rápidamente el campo a los de la tabla de destino. Sin embargo, una vez hecho esto, debemos elegir manualmente las columnas last_update y special_features en los menús desplegables de Campo de destino para cambiar su orden:
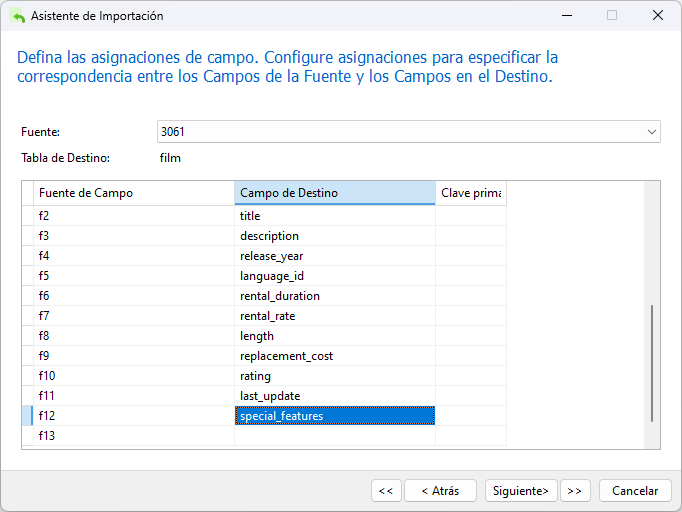
Tenga en cuenta que el campo 13 (F13) se puede ignorar sin problemas.
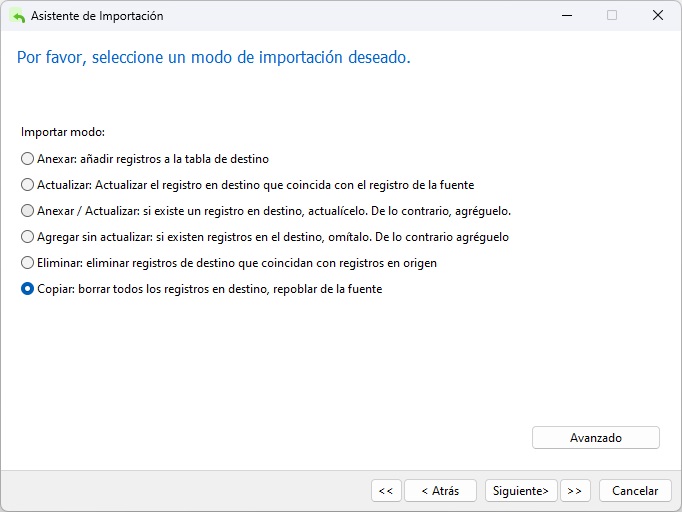
Para el modo de importación, podemos agregar o copiar los registros, ya que la tabla debe estar vacía:
Al migrar de un tipo de base de datos a otro, existe una gran posibilidad de encontrar errores de conversión de datos. Por este motivo, es una buena práctica desmarcar la casilla "Usar instrucciones de inserción extendidas" de Opciones avanzadas. Al hacerlo, Navicat emite instrucciones INSERT independientes para cada registro en lugar de combinar varias filas utilizando una sintaxis como la siguiente:
INSERT INTO `film` VALUES (1, 'African Egg', 'A Fast-Paced...'), (2, 'Rumble Royale', 'A historical drama...'), (3, 'Catherine the Great', 'A new take on...'), etc...

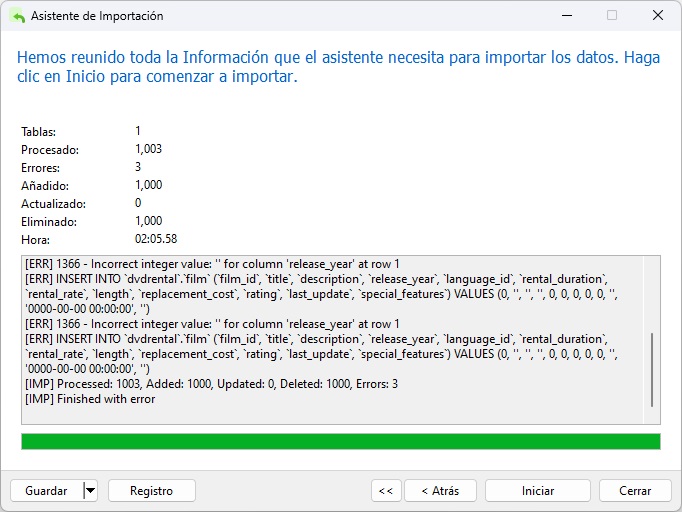
Ahora ya podemos clicar el botón de Inicio para iniciar el proceso de importación.
Como era de esperar, hubo un par de errores (3 para ser exactos), ¡pero se agregaron 1000 de 1003 filas a la tabla de destino!
Conclusión
El Asistente de importación de Navicat puede reducir drásticamente la cantidad de tiempo que se dedica a migrar datos entre repositorios heterogéneos. Admite una amplia gama de entradas, incluidas CSV, TXT, XML, DBF, fuentes de datos ODBC y más.
¿Está interesado en probar Navicat Premium Lite 17? Puede descargarlo gratis aquí. Está disponible para los sistemas operativos Windows, macOS y Linux.





