

顧名思義,關聯式資料庫(RDBMS)維持資料表之間的關係,以有意義的方式組織資料。像MongoDB 這樣的文件資料庫有時被稱為「無結構」(schemaless),因為它們並沒有像RDBMS 那樣真正落實關係。但是,雖然文件資料庫不需要與關聯式資料庫相同的預定結構,但這並不意味著它們不支持。實際上,MongoDB 允許透過內嵌和參考方法模型化文件之間的關係。在今天的文章中,我們將使用 Navicat for MongoDB嘗試每一種方法。
測試案例
A例如,我們將研究 ACME 公司的案例。他們需要以將員工與地址連結的方式儲存地址。一名員工可以擁有多個地址,這使其成為一對多(1:N)關係。這沒問題,因為就像關聯式資料庫一樣,MongoDB 中的關係可以是一對一(1:1)、一對多(1:N)、多對一(N:1)或多對多(N:N)。
以下是 Navicat JSON 檢視中 employees 文件的文件結構:

以下是 addresses 文件:

建立內嵌關係
使用內嵌方法,我們將 addresses 文件直接內嵌到 employees 文件中。我們可以在 Navicat for MongoDB 輕鬆完成,如下所示:
- 使用 JSON 檢視開啟 collection 集合並複製最後兩個文件:

- 切換到 employees 集合並編輯第一個文件:

- 將地址貼到與其關聯的員工文件中,並將它們包含在「address」陣列元素中:
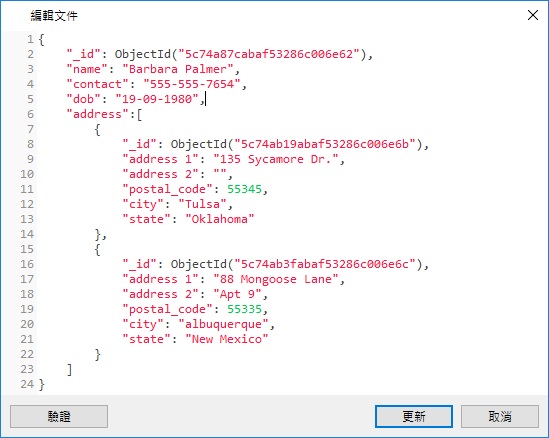
優點和缺點
此方法將所有相關資料保存在一個文件中,這使得擷取和維護變得容易。現在可以在一個查詢中擷取整個文件:

內嵌關係的缺點是,如果內嵌文件的大小不斷成長,則會對讀寫效能產生負面影響。
建立參考關係
使用此方法,員工和地址文件都將保持獨立,但員工文件將會有一個欄位參考地址文件的 id 欄位:

如上所示,員工文件包含陣列欄位「address_ids」,其中包含相應地址的 ObjectIds。使用這些 ObjectIds,我們可以查詢地址文件並從那裡取得地址的詳細資料。
優點和缺點
雖然這種方法可以更易於管理文件大小,但我們現在需要兩個查詢來取得地址的詳細資料:一個用於從 employees 文件中擷取 address_ids 欄位,另一個用於從 addresses 集合中取得地址:
var result = db.employees.findOne({"name":"Tom Smith"},{"address_ids":1})
var addresses = db.addresses.find({"_id":{"$in":result["address_ids"]}})
預告
在下一篇文章中,我們將學習如何在 Navicat for MongoDB 中使用 MongoDB 參考關係(也稱為手動參考)和 DBRefs。你可以在產品頁面了解有關它的更多資訊。更可下載功能齊全的應用程式,並在 14 天的試用期內免費使用!





