

A table column, such as one that stores first names, may contain many duplicate values. If you're interested in listing the different (distinct) values, there needs to be a way to do so without resorting to complex SQL statements. In ANSI SQL compliant databases like PostgreSQL, SQL Server, and MySQL, the way to select only the distinct values from a column is to use the SQL DISTINCT clause. It removes duplicates from the result set of a SELECT statement, leaving only unique values. In this blog article, we'll learn how to use it.
Syntax and Behavior
To use the SQL DISTINCT clause, all you need to do is insert the DISTINCT keyword between in SELECT and columns and/or expressions list like so:
SELECT DISTINCT columns/expressions FROM tables [WHERE conditions];
You may include one or more columns and/or expressions in your statement, as the query uses the combination of values in all specified columns in the SELECT list to evaluate their uniqueness. Also, if you apply the DISTINCT clause to a column that has NULL values, the DISTINCT clause will keep only one NULL and eliminate the others. In other words, the DISTINCT clause treats all NULL values as the same value.
One Column Example
A common use case for a query is to list all of the cities and/or countries of an organization's customers or users. Here's a query in Navicat Premium 16 against the classicmodels sample database:
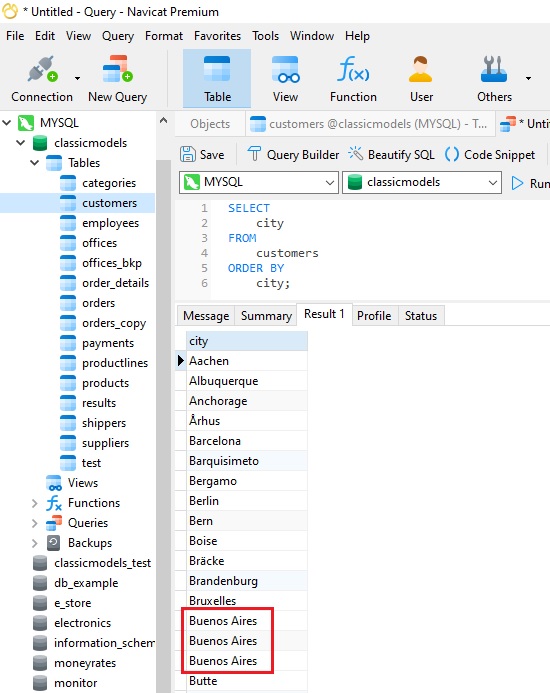
As highlighted with the red outline, there are duplicate cities.
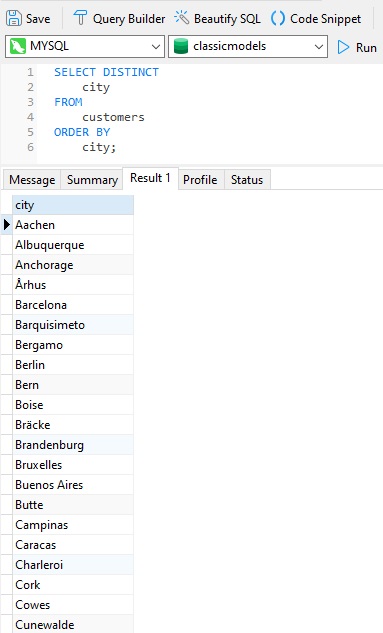
To get a list of unique cities, we can add the DISTINCT keyword to the SELECT statement:
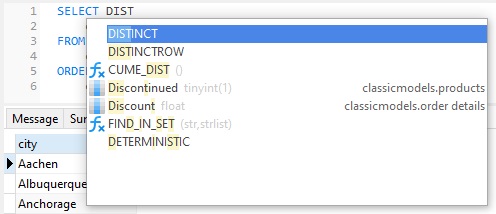
We can utilize Navicat's code-completion feature to bring up the DISTINCT keyword. Navicat displays information in drop-down lists as you type your SQL statement in the editor, it assists you with statement completion and the available properties of database objects, for example databases, tables, fields, views etc with their appropriate icons:
Multiple Column Example
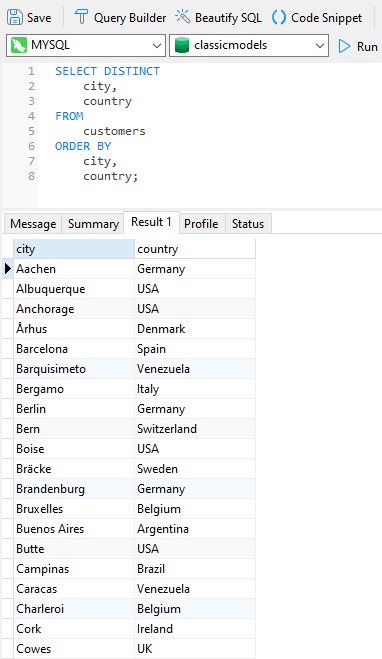
The DISTINCT keyword may also be applied to multiple columns. In that context, the query will only return rows where all of the selected columns are unique. First, let's add the country field to our last query:
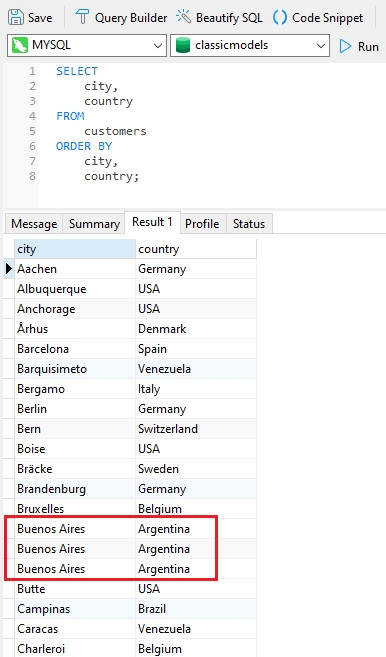
Once again, we see duplicates, which makes sense because a duplicated city will likely reside in the same country.
Once again, adding the DISTINCT keyword will cause the query engine to look at the combination of values in both city and country columns to evaluate and remove the duplicates:
DISTINCT with Null Values
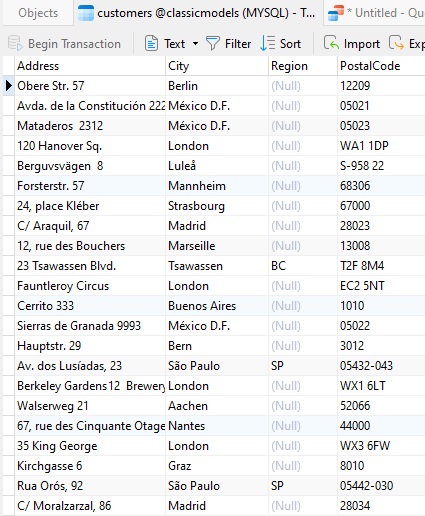
As mentioned above, the DISTINCT clause treats all NULL values as the same value so that only one instance of NULL is included in the result set. We can test that out for ourselves by querying a column such as this on in the same customers table that we queried previously:
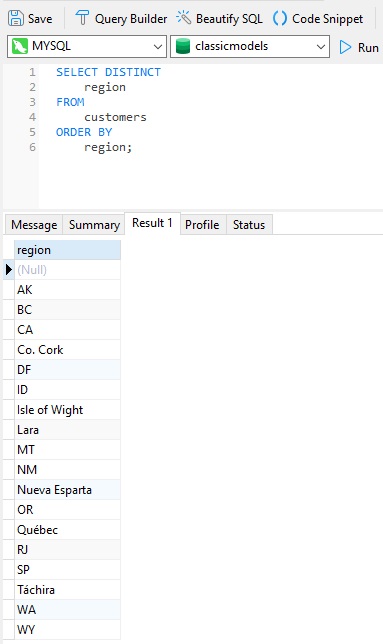
As predicted, adding the DISTINCT keyword removed all but one instance of NULLs :
Final Thoughts on Selecting Distinct Values From a Relational Database
In this blog article, we learned how to use the SQL DISTINCT clause, which removes duplicates from the result set of a SELECT statement, leaving only unique values. As we saw, it can work on one or more columns as well as NULL values. However, should you need apply an aggregate function on one or more columns, you should use the GROUP BY clause instead.







