

Recently, the subject of database indexes has come up a couple of times, specifically, in the The Downside of Database Indexing and The Impact of Database Indexes On Write Operations articles. Both pieces alluded to the fact that relational databases support a number of index types. Today's blog will provide an overview of the most common ones.
The Role of Database Indexes
In RDBMS (Relational Database Management Systems), indexes are a special object that allow the user to quickly retrieve records from the database. Typically, an index is implemented as a lookup table that has only two columns: the first column contains a copy of the primary or candidate key of a table; the second column contains a set of pointers for holding the address of the disk block where that specific key value is stored.
Two Types of Indexing Methods
Index types may be classified based on their indexing attributes. These fall into the two main categories of Primary and Secondary Indexing.
A Primary Index is an ordered file whose records are of fixed length with two fields. The first field of the index replicates the primary key of the data file in an ordered manner, and the second field contains a pointer that points to the data-block where a record containing the key is available.
Secondary indexes are indexes that store the primary key value rather than store a pointer to the data. The advantage is that, by accessing data through a primary key, there's no need for any additional data lookup, as all of the data you need can be found in the primary key's leaf pages.
The secondary Index in DBMS can be generated by a field which has a unique value for each record, and it should be a candidate key. It is also known as a non-clustering index. This two-level database indexing technique is used to reduce the mapping size of the first level.
Dense vs. sparse Indexes
In a dense index, a record is created for every search key valued in the database. This helps you to search faster but needs more space to store index records. In this Indexing, method records contain search key value and points to the real record on the disk.
A Sparse Index is an index record that appears for only some of the values in the file. Sparse Indexes helps you to resolve the issues of dense Indexing in DBMS. In this method of indexing, a range of index columns stores the same data block address, and when data needs to be retrieved, the block address will be fetched. Since sparse indexes only store index records for some search-key values, it needs less space, less maintenance overhead for insertion, and deletions. The drawback is that they are slower compared to dense indexes for locating records.
An Example of Primary and Secondary Indexing
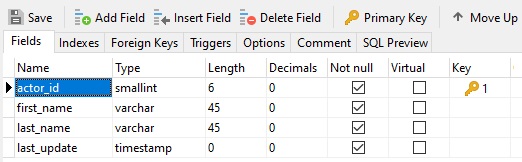
In Navicat, fields that are part of the Primary Key are identified on the Fields tab of the Table Designer:
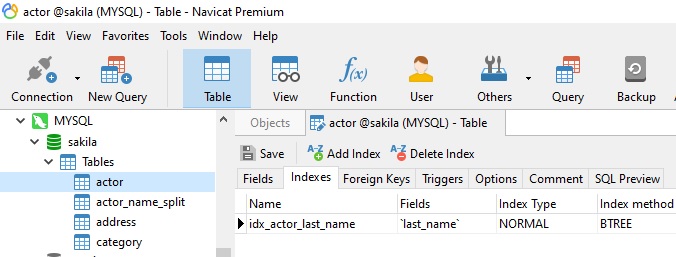
Secondary indexes are often required on tables so that users can search on fields that are not part of the Primary Key. In Navicat, all secondary indexes are listed on the Indexes tab:
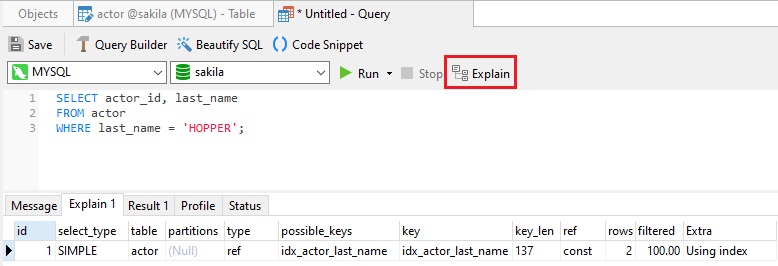
By clicking the EXPLAIN button, we can see what indexes the database is using to fetch records for a given query:
Conclusion
This blog provided an overview of the most common RDBMS index types and provided an example using Navicat Premium. If you're interested in learning more about Navicat Premium, you can try it for free for 14 days!
Rob Gravelle resides in Ottawa, Canada, and has been an IT Guru for over 20 years. In that time, Rob has built systems for intelligence-related organizations such as Canada Border Services and various commercial businesses. In his spare time, Rob has become an accomplished music artist with several CDs and digital releases to his credit.







